Federated Learning for Sentiment Analysis
Bharat Mamidibathula, Amol Agrawal, Ritvik Iyer, Aditya Pansare, Purva Singh
Project maintained by ritviyer Hosted on GitHub Pages — Theme by mattgraham
Problem Definition
Twitter is a growing social media platform that hosts a large number of online communities. People use it for a variety of things ranging from expressing personal opinions, updates or news, announcements. Every personal tweet by a user can exhibit a variety of sentiments, positive or negative. So we decided to use this to identify such negative and positive sentiments of different users.
Hence, our problem definition is “Implement Federated Learning mechanism in a peer-to-peer network, to build a classifier which classifies tweet sentiment as negative or positive.”
Introduction & Motivation
Federated learning is a great way to learn from confidential or sensitive data which can’t be uploaded to the cloud or a centralized location. This makes data privacy a critical requirement in Federated learning. We need to ensure that the sensitive data is intact and safe. Federated learning is perfect for such use cases – because instead of sending data from each distributed device to the cloud, federated learning summarizes local changes and only sends aggregate parameters to the cloud. In principle, it has several benefits over conventional machine learning setups.
The primary motivation behind choosing federated learning was that Data Privacy and Security are guaranteed since the training data in use is kept on the devices and only the model parameters are sent to the public domain. Deploying a conventional model requires access to all the dataset, which is stored in a single location. But when we talk about sensitive data, we cannot compile them and store them all at a single centralized server. Precautions need to be taken to ensure that access rights and privileges are maintained for such data and that they are stored in appropriate clients or servers. In such a scenario, deploying a convention model would mean giving the model access to all this distributed private data, which is not the safest thing to do and clearly an invasion of privacy. The Federated learning model helps here by making sure that the privacy of the data is safeguarded, while also ensuring all the data points are used for training the model. Similarly, using different data sources allows diversity within data points in terms of range, structure, and other aspects. This technique also facilitates model improvement using client data, with no need for data aggregation.
While these benefits are appealing, it poses certain challenges as well. High distributed storage capacity and high bandwidth are among the key investments that need to be made. Also, in federated learning, data is collected across multiple devices, and this can increase the attack potential, leaving it unprotected. Each device has its own specific characteristic, which could limit generalization, and it would be visible in terms of reduced accuracy or other parameters being affected. So, concerns and roadblocks like these often make its implementation challenging and require innovation to address the same.
Architecture of the system
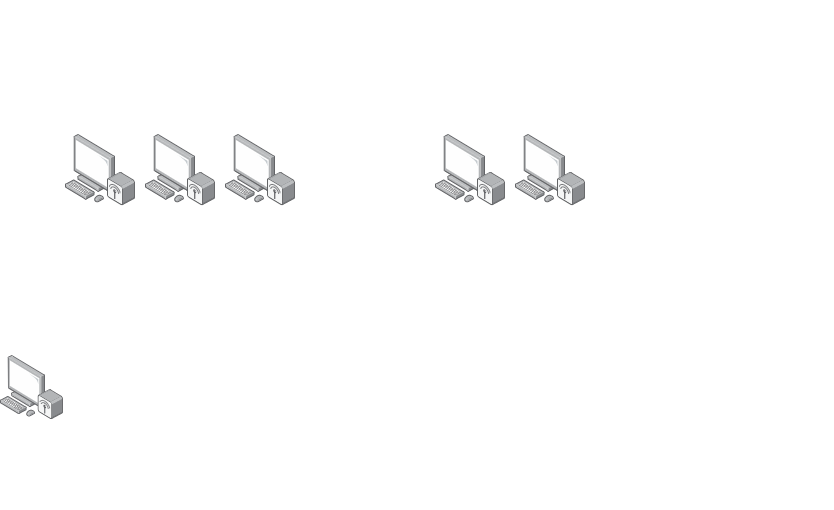 The figure above represents a P2P Federated Learning environment, where
The figure above represents a P2P Federated Learning environment, where CLIENT 1 through N are a part of a single P2P network, where each CLIENT has its own CPU and data files - DATA 1 through N. These data files are private can only be accessed by the CLIENT associated with the DATA.
Each CLIENT performs a Local Learning Step, without communicating or sharing information with other CLIENTS on the network. Then, they send their local model parameters to the CENTRAL SERVER, which uses all the parameters and performs a Global aggregation Step, to update the Final Model Parameters.
This principle is called Federated Learning, which allows for data privacy, and localized usage and training of the same. This model can now be used by a CLIENT M, which can query the central server and use the model for its own results.
Literature Survey
Deep neural networks depend on both data quantity and data quality. In the real world, we can find quality data spread across edge devices all around the world. However, aggregating this quality data to use its predictive power for training our models without violating any privacy laws can be very tricky. This is where Federated Learning comes into the picture. Federated learning has been leveraged in multiple scenarios ranging from health care to finance and vision.
Healthcare facilities spread across different countries are required to perform collaborative research to accurately diagnose certain diseases, in certain situations such as the global pandemic. However, patient information is not allowed to be shared across hospitals due to privacy reasons. In such situations, federated learning can make cooperation possible. Dianwen et. al [1] have leveraged federated learning to achieve better medical imaging models for individual sites that have small labeled datasets.
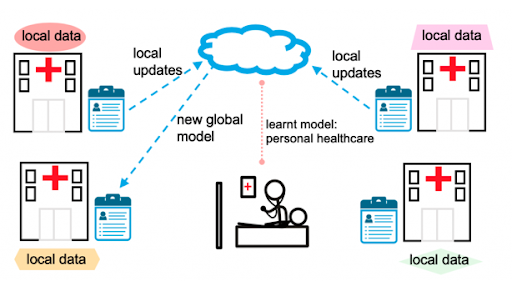
Figure: Example of Federated Learning over heterogeneous electronic medical records distributed across multiple hospitals
On the other hand, in the financial industry, multiple banks aim to cooperate with certain financial operations on a regular basis. They hope to extract information about malicious users who try to acquire loans from one bank with money loaned from another bank. In this situation, federated learning can be leveraged to share information about malicious users within banks while securing the privacy of other customers. As we can see, federated learning has multiple uses, however, for our project, we are focusing on leveraging federated learning for next word prediction.
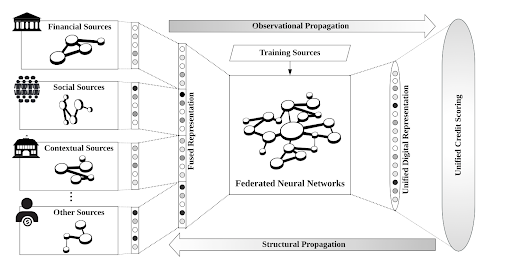
Figure: Federated Representation Learning [2]
Minh-Duc Hoang et. al [2] have leveraged federated artificial intelligence for a unified credit assessment. In their paper, they have proposed a new paradigm of unified credit assessment supported by federated learning. Next, they have also proposed a new distributed system to portray digital representations for individual credit scoring while preserving the data privacy. Finally, the authors have developed a federated learning platform for reshaping current credit assessment approaches towards data and decision orchestration [2].
Andrew et al. [3] have made use of federated learning for next-word prediction in virtual keyboards for smartphones. They have compared the FederatedAveraging algorithm with traditional server-based training using SGD and have shown that the former training algorithm achieved better precision-recall. Their work also demonstrates the flexibility of training models on clients’ devices without exporting sensitive data to the servers.
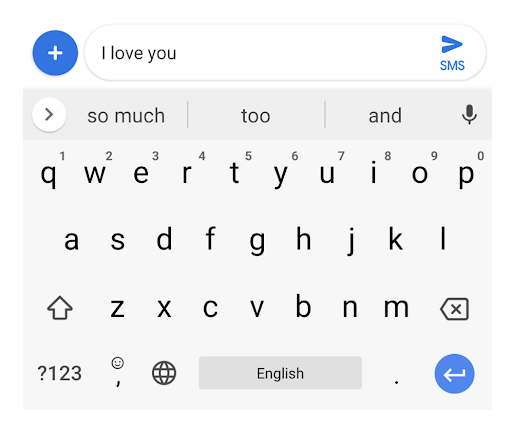
Figure: Next word predictions in Gboard. Based on the context “I love you”, the keyboard predicts “and”, “too”, and “so much”.
Chen et al. [4] have used a decentralized FederatedAvergaing algorithm to train their RNN language model. They have also approximated their federated model on the server-side with the n-gram model to deploy them on devices for faster inference. The authors have also compared their n-gram model, trained on federated learning, against traditional server-based n-gram models. Their experiments have shown that high-quality n-gram models can be trained successfully on clients’ devices with better results and without violating any data privacy laws.
Swaroop et al. [5] have leveraged federated learning (FederatedAveraging algorithm) to train their word-level CIFG-LSTM model to predict emoticon based on the text typed on the keyboard. Their experiments have also shown the feasibility of leveraging distributed on-device model training for NLP tasks while keeping the user data intact. They have also demonstrated that model trained with federated learning performs better than server-trained models and works even if poorly balanced datasets. Yang et al. [6] have leveraged federated learning for training, evaluating, and deploying their logistic regression model to improve keyboard search suggestion quality. They have discussed the cyclic nature of FL without having to access training data directly. They have shown that we can leverage FL to build and improve user experience without violating privacy laws.
Dataset
Dataset Description, Cleaning & Preparation
For our project, we made use of the same dataset that has been leveraged by Priyam Basu et. al [6]. Since hospitals are bound by patient-doctor confidentiality, extracting data/posts relevant to our project topic became difficult. As of now, our dataset contains 3096 rows of tweets. For our project, the dataset contains two columns of interest: Tweet, and Target. A subset of our dataset is shown in the below figure.
Dataset Preview [6] - ”Benchmarking Differential Privacy and Federated Learning for BERT Models”, Priyam Basu, et.al
| Index | Tweet | Target |
|---|---|---|
| 0 | Today in Selfcare: beauty ; laughs Kung Fu Panda three Wellness joy laughter selfcare therapist philadelphia | 0 |
| 1 | I get to spend New Year’s home again alone and lonely.??? | 1 |
| 2 | Depressed and lonely /: Stuck in a deep, never ending hole :( | 1 |
| 3 | If this is your response to someone saying they’re dealing with , you’re a terrible person. | 0 |
| 4 | Apparently you get a free pass just by mentioning Where was I on the free badge day??!! | 0 |
Where the Target is assigned the values as per -
| Target | Sentiment |
|---|---|
| 0 | Positive |
| 1 | Negative |
Our dataset basically contains two attributes. The first attribute, Tweet, represents a string value that defines the tweet/post shared/tweeted by the end-user in string format. The next attribute is the Target, which is a boolean value. If the target value is 0, it indicates a presence of positive spin or possibly no depression detected in the tweet. However, if the target value is 1, it indicates that the tweet most probably has a negative spin to it and the end-user who tweeted this post is likely to be depressed.
For the purposes of cleaning our data, we omitted those data rows which contained empty targets or tweets.
Dataset Preprocessing using BERT
Our data preparation strategy involved leveraging the BERT tokenizer to pre-process the data before sending the same to our model. For our project, we have leveraged the BERT-base-uncased model. To automatically download the pre-trained model, we leveraged the from_pretrained() method.

Figure: Leveraging BERT’s pre-trained model for data pre-processing
BERT primarily uses three embeddings to represent input: token embeddings, which represent the vectorized form of our input sentence. Next, we have the segment embeddings to be assigned to particular words in sentences. Finally, BERT uses position embeddings to account for the sequence of the input sentence.
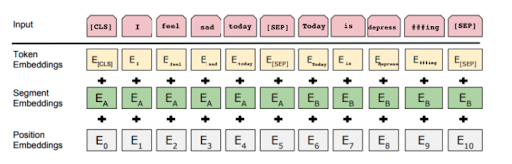
Figure: BERT’s input representation
A BERT tokenizer has many methods but for our purpose, we simply leveraged the tokenizer() method to preprocess our data. The tokenizer function returns a dictionary where we have string keys and a list of integers as values. The input_ids are the indices corresponding to each token in our sentence.

Figure: Leveraging tokenizer for encoding a single tweet row
We can also leverage tokenizer to decode our token_ids to check how BERT pre-processes/changes our data for its better understanding.

Figure: BERT adding [CLS] and [SEP] tokens to the tweet
As we can see, BERT automatically appended [CLS] and [SEP] tokens that the model expects. In general the [CLS] token is a reserved token to represent the start of a sequence, while the [SEP] token represents a separate segment or sentence. Now, in the case of batches of tweets (real representation of our dataset), BERT uses makes each tweet of equal length before passing the same as the input to the model.

Figure: Representation of how batches of tweets are pre-processed using BERT tokenizer
Here, token_type_ids indicate the model which part of inputs corresponds to the first sentence, and which part corresponds to the second sentence. Finally, the attention_mask points out which tokens the model should pay attention to and which tokens can be ignored (pad tokens in our case).

Figure: Padded representation of batches of input tweets
If we look closely, the decoded representations of input_ids contain a new special token, [PAD], which is leveraged by BERT to make the entire dataset of equal length.
Models
Word embeddings are the basis of deep learning for NLP. Selecting the right embeddings can make or break your model. Word embeddings (word2vec, GloVe) are pre-trained on text corpus from co-occurrence statistics, but are applied in a context free manner. We have seen transformers take the world by storm in the field of NLP. They rely entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs (LSTMs, GRUs, etc). There’s a lot of advantages to a transformer, like elimination of locality bias. Self-attention transformers handle long term dependencies well as well. Also, absence of recurrent layers allow significant speedup while training.
Context is of paramount importance, and it drives the behaviour of a model.
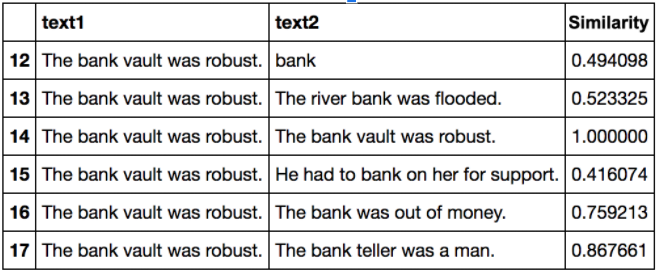
In this example, we can see that the context played an important part in deciding what meaning of bank to use in the sentence. In the pairs of sentences which had the same meaning of ‘bank’ gives higher similarity scores whereas the pairs of sentences that had different meanings of bank had lower similarity scores.
Next, we discuss the model we’re using. We are using BERT (Bidirectional Encoder Representations from Transformers) is a Transformer model with having different encoder layers and self-attention heads. BERT was pretrained. Two tasks have seen its use -
- Language Modelling (BERT predicted masked tokens from context)
- Next Sentence Prediction (BERT predicted if a particular next sentence was probable or not given the first sentence)
As a result of the training process, BERT learns contextual embeddings for words. This allows BERT to be finetuned with less resources on smaller datasets to optimize its performance on specific tasks. The tokenized sequence along with - [CLS] and [PAD] tokens, and are fed into the model where the corresponding embeddings are being extracted.
One way of getting sentence embeddings is to take embedding of [CLS] token, which is well-suited for classification problems. Another way of getting these are to globally aggregate all word embeddings. We used the former method for our task, since it is a classification task. These sentence embeddings are passed through a series of Dense layers to predict the final sentiment probabilities.
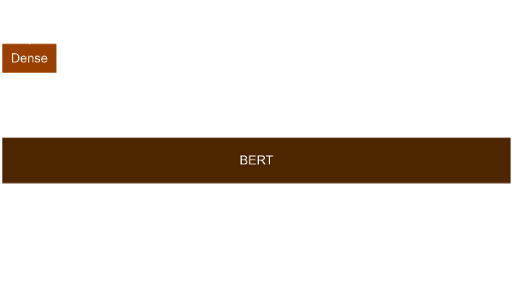
The architecture of the model is given below -
For our task, we used 3 models -
- BERT
- DistilBERT
- RoBERTa
Below is a comparative chart between the three models
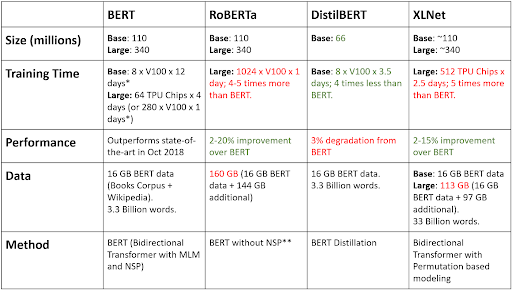
Model Parameters
We chose the following model parameters for our training process.
- Batch Size = 16
- Maximum Length = 256
- Rounds = 10
- Epochs per Round = 1
- Learning Rate = 1e-5
Clients
Crux of the federated learning task is to set up multiple clients within a network, and have them contribute to a learning task individually, and then use their parameters on a global level. We tried and tested our models with a set of client counts -> {5,10,15,20}
Results
| Model | IID (K = 10) | Non-IID (K = 10) | Non Federated | |||
|---|---|---|---|---|---|---|
| Training Time | Test Accuracy | Training Time | Test Accuracy | Training Time | Test Accuracy | |
| DistilBERT | 6973.22 | 68.82 | 7231.47 | 67.85 | 3886.29 | 73.51 |
| BERT | 14946.64 | 79.81 | 16284.2 | 79.64 | 5837.23 | 84.19 |
| RoBERTa | 7763.88 | 83.2 | 7475.51 | 80.78 | 3524.51 | 85.30 |
Model Comparisons on Examples
Below is table of sentences which we used to see how our models are predicting as well as hard cases, as compared to the ground truth.
| Sentences | Case Type | FL-BERT (Predicted) | FL-DistilBERT (Predicted) | FL-RoBERTa (Predicted) | Ground Truth |
|---|---|---|---|---|---|
my boss is bullying me… |
Easy Prediction | 1 | 0 | 1 | 1 |
i lost all my friends, i`m alone and sleepy..i wanna go home |
Easy Prediction | 1 | 1 | 1 | 1 |
SWEEEEET - San Fran is awesome!!!! Love it there |
Easy Prediction | 0 | 0 | 1 | 0 |
WOW, i AM REALLY MiSSiN THE FAM(iLY) TODAY. BADDD. |
Easy Prediction | 1 | 1 | 1 | 1 |
im meeting up with one of my besties tonight! Cant wait!! - GIRL TALK!! |
Easy Prediction | 0 | 1 | 0 | 0 |
back home now gonna miss every one |
Hard Prediction | 0 | 1 | 1 | 1 |
the free fillin` app on my ipod is fun, im addicted |
Hard Prediction | 0 | 1 | 0 | 0 |
I am so happy, I wanna die.. |
Hard Prediction | 0 | 1 | 0 | 0 |
those splinters look very painful...but you were being very heroic saving mr. Pickle |
Hard Prediction | 1 | 0 | 1 | 1 |
My modem has been offline for a week now... God bless the 3g network |
Hard Prediction | 1 | 1 | 1 | 0 |
Here, we notice that for easy predictions, FL-RoBERTa & FL-BERT performs extremely well giving 5/5 predictions on an external dataset, while FL-DistilBERT only provides 4/5.
For hard predictions, we see that FL-RoBERTa gets a prediction wrong making it 4/5, while FL-BERT gives 3/5 and FL-DistilBERT gives 1/5.
We notice that FL-RoBERTa has one of the highest accuracies on the external sample (9/10), while FL-BERT offers the next best accuracy giving 8/10. FL-DistilBERT gives the lowest accuracy giving 5/10.
Analysis & Evaluation
We will analyze our results and analyze them as per training time, test accuracy, data sampling, and client counts.
Federated vs Non Federated
We analyzed Models like BERT, DistilBERT, & RoBERTa with their Federated counterparts for training time and test accuracy.
Training Time
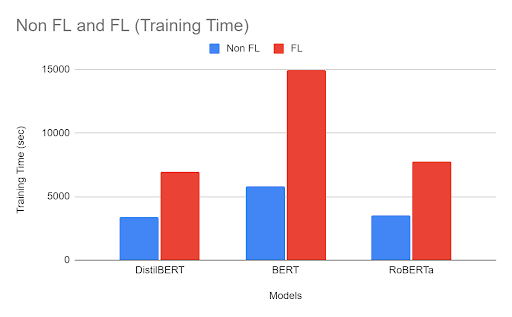
As observed, the models that were trained using federated learning took significantly longer times when compared to their non-federated counterparts. The two main reasons behind this is the network latencies and the global aggregation step being performed on the server.
Test Accuracy
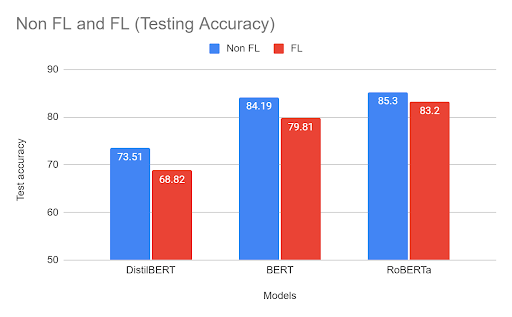
We can see that the experiments that were trained using the Federated Learning mechanism have slightly lesser accuracies. This is due to the fact that training samples on single node are mostly correlated and belongs to same class. This adds bias to the model and hence model is underfitted. However with non-FL the sampling from global pool of data draws data which is non-correlated making model learn better.
FL-Models
Now, we compared the FL Models (FL-BERT, FL-DistilBERT and FL-RoBERTa) within themselves for training time and test accuracy.
Training Time
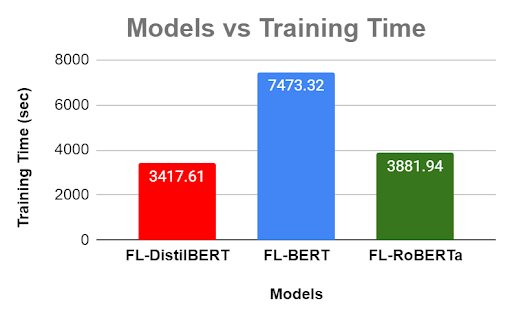
Training time for DistilBert is lesser because it has lesser parameters to train compared to BERT. However we are not sure why Roberta is taking less time compared to BERT having same number of parameters, one potential reason could be better initialization of weights.
Test Accuracy
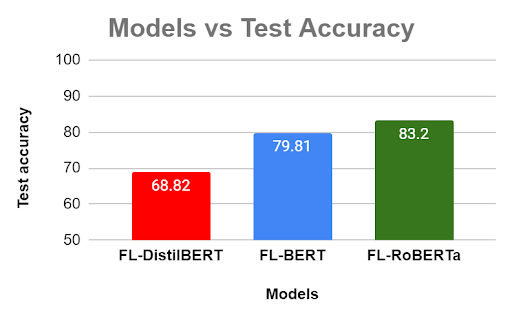
DistilBERT is the model with lesser parameters compared to BERT model. It does model pruning at the cost of the accuracy, hence lower accuracy. On the other hand, Roberta is a more robustly optimized version of BERT hence produces better accuracy then BERT.
Data Sampling
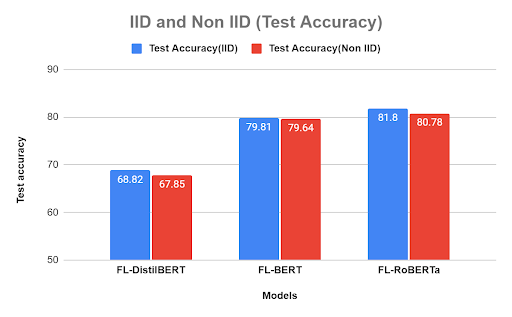
We checked for test accuracy across all three models. IID assumption makes sure that the data is independent and identically distributed which helps in training model efficiently as correlated data can add bias in the model impacting the overall accuracy as can be seen in the non-IID bars of the plots.
Overall, we could see from the results that FL-RoBERTa is a better model owing to low training time, better test accuracy exhibited across all experiments.
Number of Clients
Further, we analyzed our final model and saw how the training time and the test accuracy changes as per number of clients.
Training Time
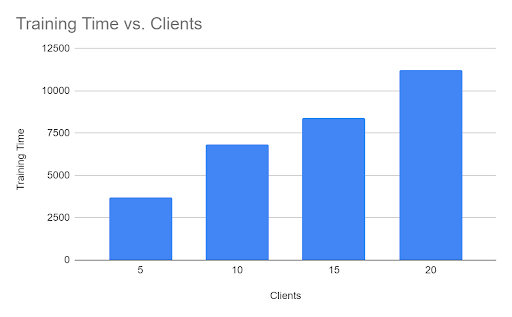
As we add clients to the P2P Network, it increases training time almost linearly as the communication overhead between client and server increases.
Test Accuracy
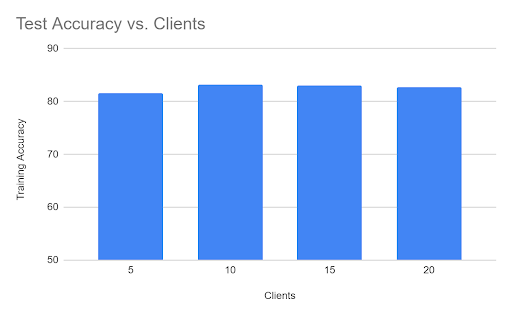
Here, as observed, the accuracy stays approximately the same despite the change in number of clients. We can infer that the accuracy does not change too drastically with the change in the number of clients.
Code Workflow
IID-Partitioning
def iid_partition(dataset, clients):
num_items_per_client = int(len(dataset)/clients)
client_dict = {}
image_idxs = [i for i in range(len(dataset))]
for i in range(clients):
client_dict[i] = set(np.random.choice(image_idxs, num_items_per_client, replace=False))
image_idxs = list(set(image_idxs) - client_dict[i])
return client_dict
Non-IID Partitioning
def non_iid_partition(dataset, clients, total_shards, shards_size, num_shards_per_client):
shard_idxs = [i for i in range(total_shards)]
client_dict = {i: np.array([], dtype='int64') for i in range(clients)}
idxs = np.arange(len(dataset))
data_labels = dataset.get_labels()
# sort the labels
label_idxs = np.vstack((idxs, data_labels))
label_idxs = label_idxs[:, label_idxs[1,:].argsort()]
idxs = label_idxs[0,:]
# divide the data into total_shards of size shards_size
# assign num_shards_per_client to each client
for i in range(clients):
rand_set = set(np.random.choice(shard_idxs, num_shards_per_client, replace=False))
shard_idxs = list(set(shard_idxs) - rand_set)
for rand in rand_set:
client_dict[i] = np.concatenate((client_dict[i], idxs[rand*shards_size:(rand+1)*shards_size]), axis=0)
return client_dict
Model Definition
# Importing BERT-base pretrained model
bert = AutoModel.from_pretrained('bert-base-uncased')
# Load the BERT tokenizer
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')

Model Architecture
class BERT_Arch(nn.Module):
def __init__(self, bert):
super(BERT_Arch, self).__init__()
self.bert = bert
self.dropout = nn.Dropout(0.1)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(768,512)
self.fc2 = nn.Linear(512,2)
self.softmax = nn.Softmax(dim=1)
# Define the forward pass
def forward(self, sent_id, mask):
_, cls_embedding = self.bert(sent_id, attention_mask=mask)
x = self.fc1(cls_hs)
x = self.relu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.softmax(x)
return x
Experiments
We experimented with different number of clients, different types of NLP based models, different data sampling techniques, and compared the performance in both time and accuracy. Also compared the performance vs the original non-federated case. In addition to that, we used data augmentation from a notebook by Kazanova on Kaggle in order to increase the size of the dataset.
We also experimented with the model by exploring different kinds of output embeddings that were used for each model - [CLS] embeddings vs. mean of embeddings vs. element-wise max of embeddings vs. Concatenation of min + max embeddings) and different activations, dense layers sizes, etc.
We also modified the training mechanism to incorporate a fractional number of clients to simulate the real world scenario of have only a fraction of the clients being online at a single time. This would help us with network congestion, performance bottleneck and make sure that there are only a fixed number of clients performing learning tasks at a time to provide uniformity with results.
Moving on to some things that didn’t work, we focused on the topic of next word prediction. However, we were not able to find suitable next word prediction datasets, while existing corpi did not suit our purpose. Moved towards Face Detection/Object detection but the training times were too high for the dataset in use and also the resources that we had (Google Colab) were not sufficient. We also, tried sentence generation using StackOverflow dataset. Colab timing out before training the model for adequate number of epochs. Finally shifted towards Depression dataset for sentiment analysis as the need for federated learning in clearly observed (privacy issues).
We also, tried to experiment with other Federation Learning policies like Federated Learning with Matched Averaging [8]. However, it was too intrusive to our pipeline and finally decided against it.
Future Scope & Conclusion
- This project shows that using Federated Learning mechanism for Sentiment Analysis is a viable option especially when we deal with sensitive data.
- We can extend this architecture to a multitude of healthcare & wellness systems where sentiment analysis could help us with important information regarding patients’ wellbeing.
- A more detailed analysis would be to experiment with the models on different machines in order to simulate all the components of the overall federated system (network issues, synchronization, etc.)
Link to the code package - Code Package
References
[1] D. Ng, X. Lan, M. Min-Szu Yao, W.P. Chan, and M. Feng, “Federated learning: a collaborative effort to achieve better medical imaging models for individual sites that have small labelled datasets”, Quantitative Imaging in Medicine and Surgery, 2021.
[2] M.-D Hoang, L. Le, A.-T. Nguyen, T. Le, and H.D. Nguyen, “Federated artificial intelligence for unified credit assessment”, arXiv prepreint arXiv:2105.09484, 2021.
[3] A. Hard, K. Rao, R. Mathews, S. Ramaswamy, F. Beaufays, S. Augenstein, H. Eichner, C. Kiddon, and D. Ramage, “federated learning for mobile keyboard prediction”, arXiv preprint arXiv:1811.03604, 2018.
[4] M. Chen, A. T. Suresh, R. Mathews, A. Wong, C. Allauzen, F. Beaufays, and M. Riley, “Federated learning of n-gram language models”, arXiv preprint arXiv:1910.03432, 2019.
[5] S. Ramaswamy, R. Mathews, K. Rao, and F. Beaufays, “Federated learning for emoji prediction in a mobile keyboard”, arXiv preprint arXiv:1906.04329, 2019.
[6] T. Yang, G. Andrew, H. Eichner, H. Sun, W. Li, N. Kong, D. Ramage, and F. Beaufays, “Applied federated learning: Improving google keyboard query suggestions”, arXiv preprint arXiv:1812.02903, 2018.
[7] P. Basu, T.S. Roy, R. Naidu, Z. Muftuoglu, S. Singh, F. Mireshgallah, “benchmarking Differential Privacy and Federated Learning for BERT Models”, arXiv preprint arXiv:2106.13973.
[8] Wang, Hongyi, et al. “Federated learning with matched averaging.” arXiv preprint arXiv:2002.06440 (2020).